
打开你想要爬取的商品页面,点击评论
打开开发者工具,快捷键F12键,或者鼠标右键-->检查-->网络
找到名为productPageComments.action开头的js文件
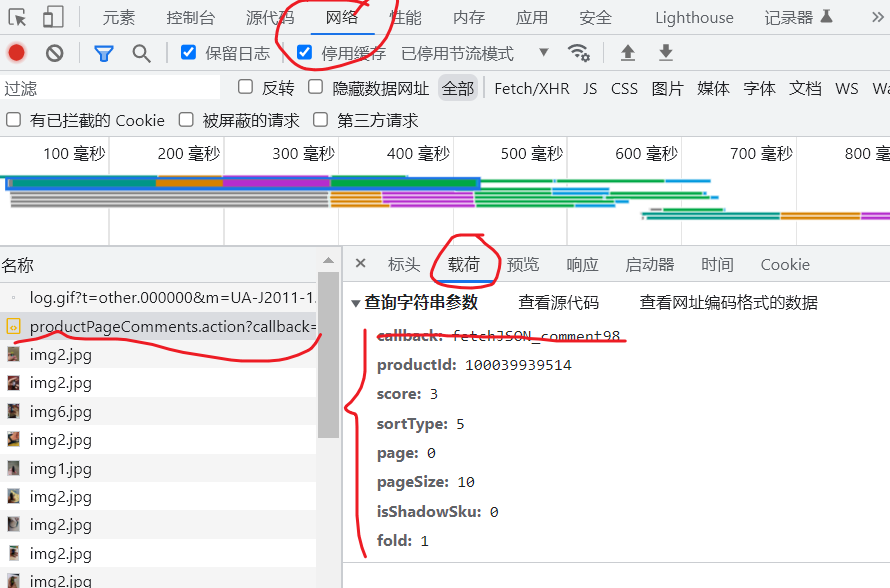
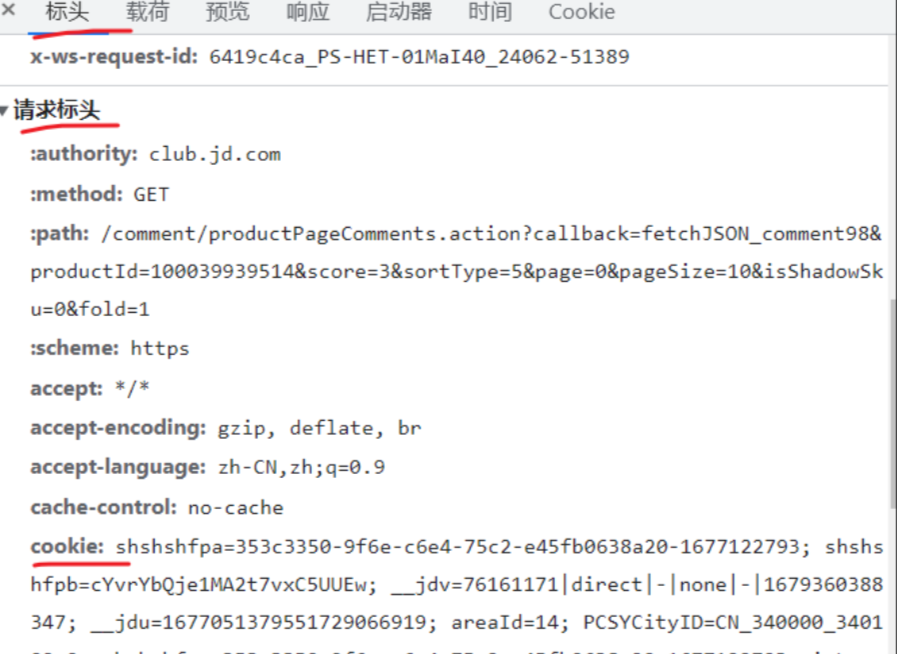
复制你的cookie到下面的代码对应项里
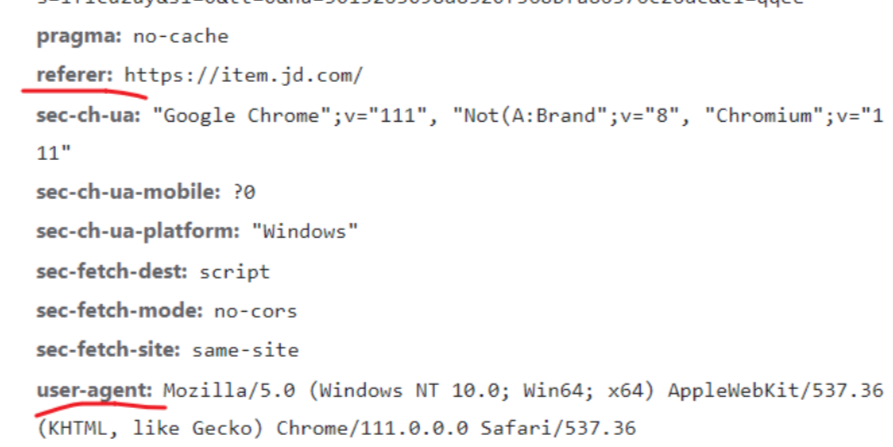
复制你的user-agent到下面的代码中
import csv
import requests
import json
def begain_scraping(page):
# 构造商品地址
url_jd = 'https://sclub.jd.com/comment/productPageComments.action?callback'
# 网页信息
vari_p = {
# 商品ID
'productId': 100009751121, # 换成你想爬取的商品ID就可以了
'score': 0,
'sortType': 5,
# 爬取页面
'page': page,
'pageSize': 10,
}
# UA伪装
headers = {
'cookie': '这里复制上你的cookie',
'referer': 'https://item.jd.com/', # 换成你想爬取的商品ID
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
comment_jd = requests.get(url=url_jd, params=vari_p, headers=headers)
return comment_jd
def python_comments(comment_resp):
"""
爬取数据并且写入评论
:param comment_resp:
:return:
"""
comment_js = comment_resp.text
comment_dict = json.loads(comment_js)
comments_jd = comment_dict['comments']
for comment in comments_jd:
user = comment['nickname']
color = comment['productColor']
comment_python = comment['content']
comment_python = comment_python.replace('\n', '')
# 写入文件
with open('comments_jd.csv', 'a', newline='')as csv_file:
rows = (user, color, comment_python)
writer = csv.writer(csv_file)
writer.writerow(rows)
def main(start):
"""
开始爬取
:return:
"""
# 第一步解析网页
comments_jd = begain_scraping(start)
# 第二步 爬取评论并保存文件
python_comments(comments_jd)
if __name__ == '__main__':
# 循环100次
for i in range(100):
main(start=i)爬取后得到的csv文件(部分)

成功拿到了数据就可以开始愉快的进行数据处理和数据分析啦!

Comments NOTHING