
问答系统是NLP中最复杂的场景之一,根据查阅资料和个人的理解,简单展示问答系统的设计流程
绿茶产品搜索模型设计
绿茶产品的搜索模型主要完成的工作是将用户输入的问题,导入到知识库中,通过将用户问题和知识库中提前定义好的问题进行相似度匹配,选出最接近用户意图的模板问题,在知识库中完成对问题的查找,为用户生成问题的回答。
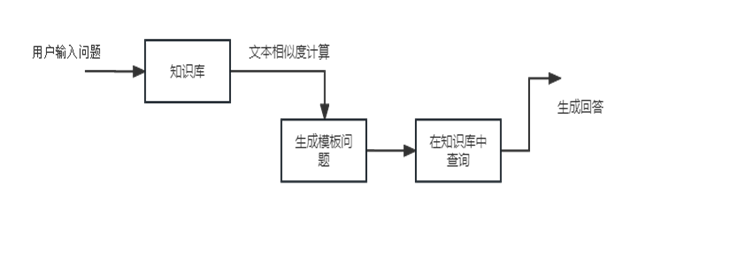
绿茶产品搜索系统流程设计
基于构建出的绿茶产品知识图谱进行搜索,本质上是一个问答的过程。我们设计的搜索系统包括七个模块,如下图所示,分别是提出问题、中文分词、实体检测、问题分类、模板匹配、图数据库查询和生成回答。
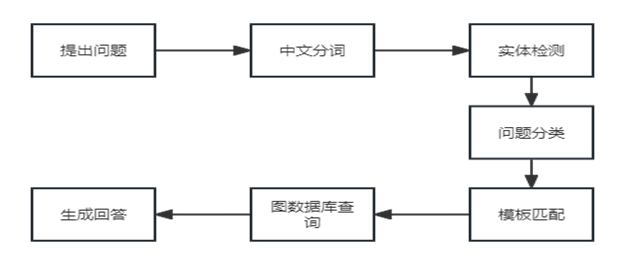
(1)输入问题
用户可以逐条输入有关京东平台上绿茶产品的相关问题。例如:“京东京造信阳毛尖的售价为?”、“京东京造信阳毛尖的包装形式是什么?”等。
(2)中文分词
对于一个问句我们需要分词,将问句中的自然语言分解成一个个词语,在这些词语中有下面环节需要使用到的实体、问题类别和关系。
(3)实体检测
在实体检测这一环节,获取问题中的实体关键词,比如问题“京东京造信阳毛尖的包装形式是什么?”,那么经过分析首先必须找到这个问题的实体是商品京东京造信阳毛尖,才可以进行下一步。
(4)问题分类
目的获取,对于上面的问题,我们只获取了实体还不够,比如上面,只有商品,还需要找到问题的真实目的。上面问题的目的是包装形式。
(5)模板匹配
在问题理解步骤中,本问答系统选择模板匹配的方法,将用户输入的问题与事先预设好的问题模板进行一对一匹配,两个问题在进行相似度的对比时采用了Python库提供的fuzz中的token_sort_ratio方法将两个句子忽略顺序进行模糊匹配,每两个句子对比后都会生成一个得分(开始时最高得分被设置成一个负数),如果当前对比的问题的得分高于最高得分则将该问句更新为最终问题,并更新最高得分。否则进行下一个问句的对比。反复这个过程。最后程序就能选择出与用户提出的问题最相似的模板问题作为最终问题进行下一步骤。在下表中展示了一部分预设的搜索问题模板。
| 序号 | 问题类别 问题模板 | |
| 1 | 功效 | XX商品有什么功效? |
| 2 | 毛重 | XX商品的毛重为多少? |
| 3 | 价格 | XX商品的价格为多少? |
| 4 | 包装 | XX商品的包装形式是什么? |
| 5 | 形状 | XX绿茶是什么形状? |
| 6 | 品牌 | XX绿茶是什么品牌? |
(6)图数据库查询
在对Neo4j图数据库进行相关查询时,使用的是图数据库Cypher语句,在前面几步中我们依次获得了查询的实体,查询的目的和完整问题。有了这些要素我们就可以构建查询语句了,通过构建出完整的查询语句带入到图数据库中查询根据查询结果,系统会自动生成答案返回给用户。
绿茶产品推荐模型设计
绿茶产品的推荐模型主要完成的工作是将用户输入的产品特征,导入到知识库中,将特征关键词构建成查询语句,通过将这条查询语句和知识库中存在的模板问题进行相似度匹配,选出最接近该用户需求的问题,在知识库中完成对具有该特征产品的查找,从而生成为用户推荐的产品名称。
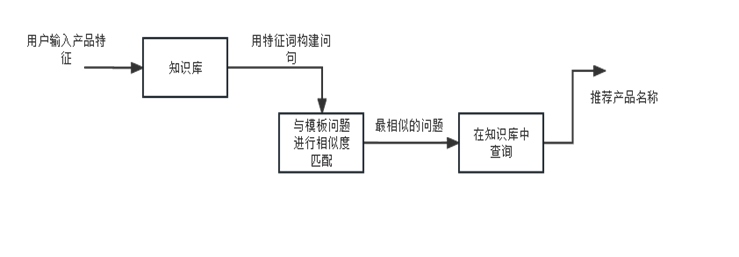
绿茶产品推荐系统流程设计
我们要完成的基于绿茶产品知识图谱的产品推荐系统,简单来说就是通过用户输入的产品特征,将这一特征关键词在数据库中进行寻找实现相关绿茶产品的推荐。系统包括五个模块,如下图所示,分别是输入特征、问题分类、模板匹配、图数据库查询和生成推荐产品。

(1)输入特征
用户可以输入绿茶产品的相关特征。这些特征往往都可以在上述的产品层次特征中找到。例如:“包装好看”、“护肝降脂”“颗粒饱满”等。
(2)生成问题
针对一个特征我们需要将其转换成一个问题,例如:对于“护肝降脂”这个特征,我们需要生成一个完整的问题即“那些茶叶具有护肝降脂的功效?”以便进行模板匹配。
(3)模板匹配
问题模板匹配的方式和上述搜索匹配过程是一致的。程序最后能选择出与用户提出的特征关键词构成的问题最相似的模板问题作为最终问题进行下一步骤。在下表中展示了一部分预设的推荐问题模板。
| 序号 | 类别 问题模板 | |
| 1 | 品鉴 | 哪些绿茶品鉴起来为香醇醇厚? |
| 2 | 功效 | 那些绿茶有护肝减肥的功效? |
| 3 | 品质 | 哪些茶叶的品质均匀饱满? |
| 4 | 外观设计 | 哪些产品设计看起来高端大气? |
| 5 | 品牌 | 哪些产品是碧螺春品牌? |
| 6 | 形状 | 哪些绿茶的形状是条形? |
(4)图数据库查询
依然使用图数据库的Cypher语句,在前面几步中我们以一个关键词为起点得到了一个完整的问题。比如问题“哪些绿茶品鉴起来为香醇浓厚?”涉及到的三元组为:xx商品-品鉴-香醇浓厚,通过这个三元组结构带入图数据库中即可得到所有的品鉴为香浓醇厚绿茶商品。将这些商品作为回答返回给用户。即完成了要实现的推荐效果。
应用效果展示
搜索应用
我们构建的问答系统可以解析输入的自然语言问句,通过问题模板匹配生成对应的Cypher声明式图查询语句,带入数据库中寻找答案并返回。比如下图的示例,用户的输入的问题是“京东京造信阳毛尖品鉴起来怎么样?”通过匹配提取出“pinjian”为问题类别,标记本次问题的类别为品鉴。通过关键词提取,提取出京东京造信阳毛尖(商品实体)和信阳毛尖(品牌实体)两个关键词,选择商品实体京东京造信阳毛尖作为Cypher语句拼接,最后得到的查询语句为:
MATCH (n:绿茶商品名称)-[:品鉴]-(m:品鉴) WHERE n.name = "京东京造信阳毛尖" AND m.name = "京东京造信阳毛尖" RETURN m.pinjian最终在数据库中完成查询,返回本次问题的答案口感甘甜。

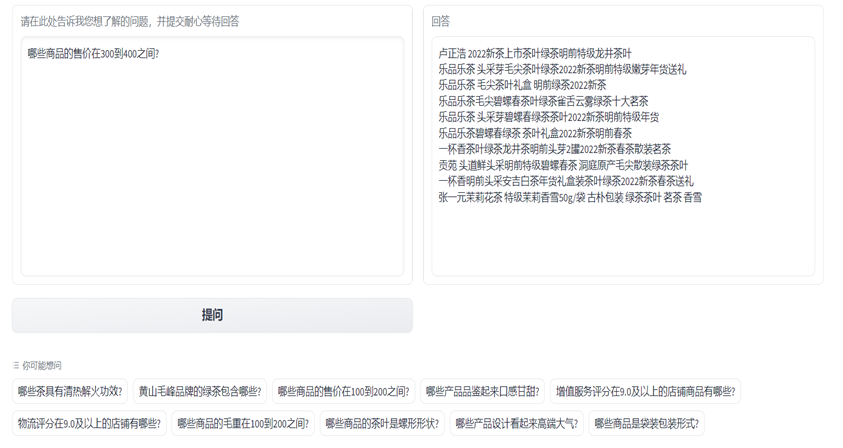
为了方便消费者使用该问答系统,将该段程序利用Gradio生成一个可交互的页面。左侧为提问输入区,右侧为回答输出区。下侧提供了常见的问题示例。用户可以在左侧输入框内输入想要提问的具体问题,通过点击提问按钮。具体的问题将通过问答系统的流程,生成的答案在右侧为用户显示。如下图中用户在左侧输入了“哪些商品的售价在300到400之间?”右侧的回答中给出了京东上10款价格在300到400之间的绿茶产品。
推荐应用
构建出的推荐系统可以解析用户输入的产品特征关键词,通过关键词模糊匹配的方法,生成对应的模板问题,随后生成对应的Cypher声明式图查询语句,带入数据库中得到用户可能最需要的答案并返回。比如下图的示例,用户的输入产品特征关键词的是“提神益思”。通过匹配将其转换成模板问题“那些茶有提神益思功效?”识别出“gongxiao”为问题类别,标记本次问题的类别为功效。通过关键词提取,提取出“提神益思”这个关键词,完成 Cypher语句拼接,最后得到的查询语句为:
MATCH (n:绿茶商品名称)-[:功效]-(m:功效)WHERE m.gongxiao = "提神益思" AND m.name = n.name RETURN m.name最终在数据库中完成查询,输出所有饮用后具有提神益思功效的所有茶叶商品名称推荐给用户。

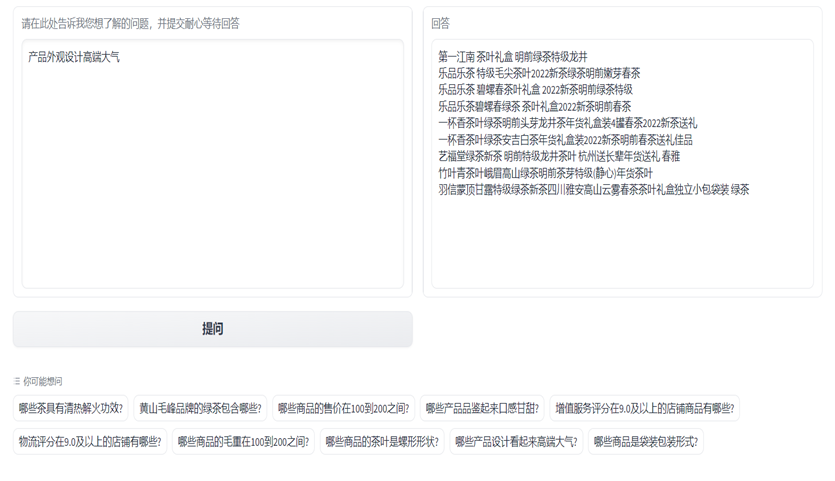
为了方便消费者使用该推荐系统,将该程序套用上面生成可交互的页面。左侧为产品特征关键词输入区,右侧为回答输出区。用户可以在左侧输入框内输入自己对绿茶产品特点的需求,通过点击提问按钮。系统将通过推荐系统的流程,生成最符合用户要求的产品名称并在右侧文本框内显示。如下图中用户在左侧输入了“产品外观设计高端大气”。在右侧的回答中给出了京东上9款产品外观设计高端大气的绿茶产品,为用户购买产品提供了参考。
部分代码展示
生成数据库Cypher语句
import re
class TempMethod:
def __init__(self, graph, template_path):
self.name = self.load_word_list('data/ori_data/name.txt')
self.shape = self.load_word_list('data/ori_data/shape.txt')
self.gongxiao = self.load_word_list('data/ori_data/gongxiao.txt')
self.package = self.load_word_list('data/ori_data/package.txt')
self.pinpai = self.load_word_list('data/ori_data/pinpai.txt')
self.pinzhi = self.load_word_list('data/ori_data/pinzhi.txt')
self.pinjian = self.load_word_list('data/ori_data/pinjian.txt')
self.search = self.load_word_list('data/ori_data/search.txt')
self.chatang = self.load_word_list('data/ori_data/chatang.txt')
self.sheji = self.load_word_list('data/ori_data/sheji.txt')
self.gweight = self.load_word_list('data/ori_data/gweight.txt')
self.pingfen = self.load_word_list('data/ori_data/pingfen.txt')
self.template_dict = {}
self.graph = graph
self.word_del = re.compile(r'(xx形状|xx包装形式|xx功效|xx品牌|xx品质|品质是xx|品质xx|xx到xx之间|物流评分在xx及以上|增值服务评分在xx及以上|xx)')
self.relation_map = {'pinjian': '品鉴', 'pinzhi': '品质', 'gongxiao': '功效', 'shape': '形状',
'gweight': '毛重', 'package': '包装形式', 'pinpai': '品牌', 'name': '绿茶商品名称',
'chatang': '茶汤', 'sheji': '设计', 'price': '售价', 'zengzhi': '增值', 'wuliu': '物流'}
with open(template_path, encoding='utf8') as f:
temp_label = ''
for line in f:
if not line.strip():
continue
if line.strip().startswith('#'):
temp_label = line.strip()[1:]
self.template_dict[temp_label] = []
else:
self.template_dict[temp_label].append(line.strip())
return
def load_word_list(self, path):
temp_list = []
with open(path, encoding='utf8') as f:
for line in f:
temp_list.append(line.strip())
return temp_list
def match(self, question):
for key, val in self.template_dict.items():
for template in val:
real_temp = self.word_del.sub('', template)
if question.find(real_temp) >= 0:
return key
def relation_query(self, key, question_type, type=0):
query_res = ''
if type == 0:
query_res = self.graph.run(
"MATCH (n:绿茶商品名称)-[:%s]-(m:%s) "
"WHERE n.name = $name AND m.name = $name "
"RETURN m.%s " % (self.relation_map[question_type], self.relation_map[question_type], question_type),
{"name": key},
)
if type == 1:
query_res = self.graph.run(
"MATCH (n:绿茶商品名称)-[:%s]-(m:%s) "
"WHERE m.%s = $name AND m.name = n.name "
"RETURN m.name" % (self.relation_map[question_type], self.relation_map[question_type], question_type),
{"name": key}
)
if type == 2:
query_res = self.graph.run(
"MATCH(n:绿茶商品名称) "
"RETURN n.name "
)
if type == 3:
query_res = self.graph.run(
"match(m:%s) "
"where $name0 <= m.%s <= $name1 "
"return m.name" % (self.relation_map[question_type], question_type),
{"name0": key[0], "name1": key[1]}
)
if type == 4:
query_res = self.graph.run(
"match(m:%s) "
"where m.%s >= $name0 and m.%s <> '暂无' "
"return m.name" % (self.relation_map[question_type], question_type, question_type),
{"name0": key}
)
return query_res
def generate_answer(self, question_type, question):
query_res_list = []
gongxiao_list = self.r_gongxiao.findall(question)
name_list = self.r_name.findall(question)
shape_list = self.r_shape.findall(question)
package_list = self.r_package.findall(question)
pinpai_list = self.r_pinpai.findall(question)
pinzhi_list = self.r_pinzhi.findall(question)
pinjian_list = self.r_pinjian.findall(question)
search_list = self.r_search.findall(question)
chatang_list = self.r_chatang.findall(question)
sheji_list = self.r_sheji.findall(question)
gweight_list = self.r_gweight.findall(question)
pingfen_list = self.r_pingfen.findall(question)
print("关键词提取:")
if gongxiao_list:
print(gongxiao_list)
if name_list:
print(name_list)
if shape_list:
print(shape_list)
if package_list:
print(package_list)
if pinpai_list:
print(pinpai_list)
if pinzhi_list:
print(pinzhi_list)
if pinjian_list:
print(pinjian_list)
if search_list:
print(search_list)
if chatang_list:
print(chatang_list)
if sheji_list:
print(sheji_list)
if gweight_list:
print(gweight_list)
if pingfen_list:
print(pingfen_list)
if question_type == 'gongxiao':
# 主要有两种类型的问题:1.xx是什么的? 2.xx有哪些?
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif gongxiao_list:
for item in gongxiao_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'package':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif package_list:
for item in package_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'shape':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif shape_list:
for item in shape_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'pinpai':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif pinpai_list:
for item in pinpai_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'pinzhi':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif pinzhi_list:
for item in pinzhi_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'pinjian':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif pinjian_list:
for item in pinjian_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'sheji':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif sheji_list:
for item in sheji_list:
query_res = self.relation_query(item, question_type, type=1)
query_res_list.append(query_res)
if question_type == 'gweight':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif gweight_list:
if len(gweight_list) == 2:
query_res = self.relation_query(gweight_list, question_type, type=3)
query_res_list.append(query_res)
if question_type == 'price':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif gweight_list:
if len(gweight_list) == 2:
query_res = self.relation_query(gweight_list, question_type, type=3)
query_res_list.append(query_res)
if question_type == 'name':
if search_list:
for item in search_list:
query_res = self.relation_query(item, question_type, type=2)
query_res_list.append(query_res)
if question_type == 'zengzhi':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif pingfen_list:
for item in pingfen_list:
query_res = self.relation_query(item, question_type, type=4)
query_res_list.append(query_res)
if question_type == 'wuliu':
if name_list:
for item in name_list:
query_res = self.relation_query(item, question_type, type=0)
query_res_list.append(query_res)
elif pingfen_list:
for item in pingfen_list:
query_res = self.relation_query(item, question_type, type=4)
query_res_list.append(query_res)
return query_res_list问题模糊匹配
from fuzzywuzzy import fuzz
fileHandler = open("data/question_template.txt", "r", encoding='UTF-8')
listOfLines = fileHandler.readlines()
fileHandler.close()
def my_re(text):
question = text
score = -1
for line in listOfLines:
# token_set_ratio() 忽略顺序匹配
n_score = fuzz.token_sort_ratio(text, line.strip())
if n_score > score:
question = line.strip()
score = n_score
return question
交互页面
import gradio as gr
from py2neo import Graph
import my_re
from template_method import TempMethod
# 连接neo4j数据库
graph = Graph("http://localhost:7474/", auth=("neo4j", '123456'))
# 加载问题模板
c = TempMethod(graph, 'data/question_template.txt')
# 主函数
def lc_rec(text):
re_text = my_re.my_re(text)
question_type = c.match(re_text)
query_res_list = c.generate_answer(question_type, re_text)
ans = ""
for query_res in query_res_list:
for d in query_res.data():
for key, val in d.items():
ans += val + "\n"
return ans
with gr.Blocks() as lcrec:
with gr.Row():
with gr.Column():
my_question = gr.Textbox(lines=13, placeholder="试试下面的问题:\n 列举一下有什么商品? 展示所有茶叶?"
, label="请在此处告诉我您想了解的问题,并提交耐心等待回答")
my_btn = gr.Button(value="提问")
with gr.Column():
my_answer = gr.Textbox(lines=13, placeholder="回答在这里", label="回答")
my_btn.click(lc_rec, inputs=my_question, outputs=my_answer)
examples = gr.Examples(examples=["哪些茶具有清热解火功效?", "黄山毛峰品牌的绿茶包含哪些?", "哪些商品的售价在100到200之间?",
"哪些产品品鉴起来口感甘甜?", "增值服务评分在9.0及以上的店铺商品有哪些?", "物流评分在9.0及以上的店铺有哪些?",
"哪些商品的毛重在100到200之间?", "哪些商品的茶叶是螺形形状?", " 哪些产品设计看起来高端大气?",
"哪些商品是袋装包装形式?"],
inputs=[my_question], label="你可能想问"),
lcrec.launch()
Comments NOTHING