
本篇文章将从Pytorch搭建环境,介绍相关API,并给出完整代码用Pytorch搭建你的神经网络。这篇文章也是机器学习入门的最后一章。
环境配置
参考文章:torch.cuda.is_available()返回false——解决办法
进入官网https://pytorch.org/get-started/locally/#no-cuda-1
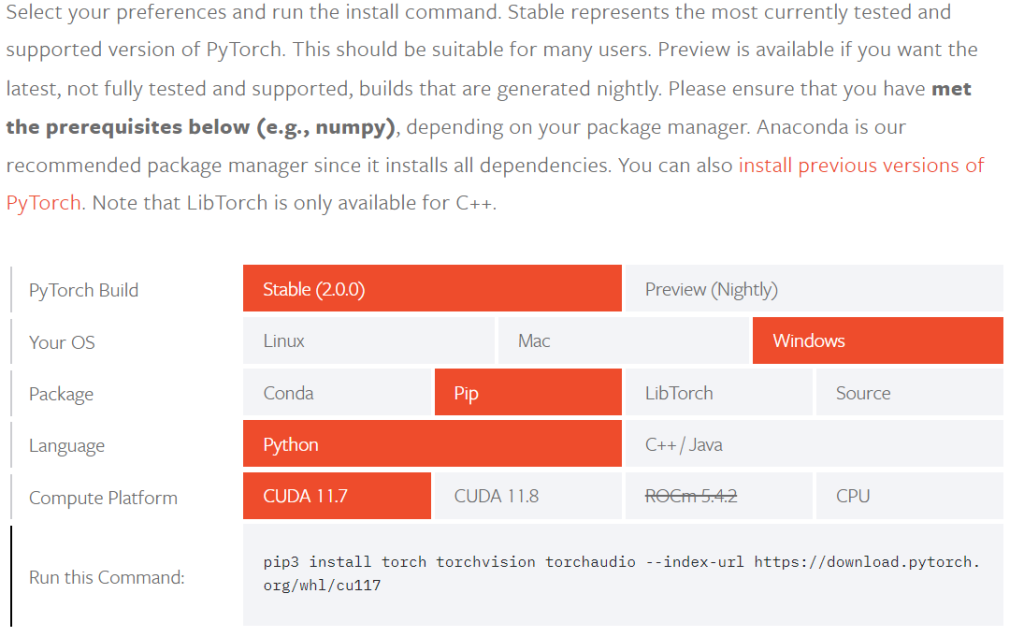
在anaconda prompt环境下输入下面的命令即可安装pytorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117常用API介绍
torch.nn.Linear()
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)in_feature: nn.Linear 初始化的第一个参数,即当前这层神经网络要输入多少个节点。
out_feature: nn.Linear 初始化的第二个参数,即当前这层神经网络要输出多少个节点。
bias: 表示是否加入学习的偏置值,为True时表示加入偏置值。
device:表示这层神经网咯训练时的环境 cpu/gpu。
dtype:表示数据处理时数据的类型 整形/浮点型。
torch.nn.CrossEntropyLoss()
torch.nn.CrossEntropyLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction='mean',label_smoothing=0.0)最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。
说明:
①交叉熵损失函数会自动对输入模型的预测值进行softmax。因此在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层。
②nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss()。
torch.nn.Module
在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__ init __构造函数和forward这两个方法。但有一些注意技巧:
(1)一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__ init __()中,当然也可以把不具有参数的层也放在里面。
(2)一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数 __ init __ 里面,则在forward方法里面可以使用nn.functional来代替。 (3)forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
torch.manual_seed()
设置随机种子,方便下次复现实验结果。
torch.from_numpy()
把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变。
optim.SGD()
要构造一个Optimizer,你必须给它一个包含参数(必须都是Variable对象)进行优化。然后,你可以指定optimizer的参数选项,比如学习率,权重衰减等。具体参考torch.optim中文文档。
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)optimizer.zero_grad()
清空过往梯度。因为grad在反向传播的过程中是累加的,也就是说上一次反向传播的结果会对下一次的反向传播的结果造成影响,则意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需要把梯度清零。
loss.backward()
对损失函数进行求导,获取当前梯度(反向传播)。
optimizer.step()
实现对训练模型中权重和偏置值(网络中可训练参数)的自更新。
loss.item()
1.item()取出张量具体位置的元素元素值 2.并且返回的是该位置元素值的高精度值 3.保持原元素类型不变;必须指定位置
4.一般用在求loss或者accuracy时,使用.item()
model.parameters()
保存的是Weights和Bais参数的值,会返回一个生成器(迭代器)。
优化器的差别与选择
从某博客上看到的对常用优化器的解释,主要参考加速神经网络训练 (Speed Up Training)教程比喻出来方便大家学习,如果想知道更加详细以及官方的解答,可以参考各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
Stochastic Gradient Descent (SGD)
SGD是最基础的优化方法,普通的训练方法, 需要重复不断的把整套数据放入神经网络NN中训练, 这样消耗的计算资源会很大。当我们使用SGD会把数据拆分后再分批不断放入 NN 中计算。每次使用批数据, 虽然不能反映整体数据的情况, 不过却很大程度上加速了 NN 的训练过程, 而且也不会丢失太多准确。
Momentum
Momentum 传统的参数 W 的更新是把原始的 W 累加上一个负的学习率(learning rate) 乘以校正值 (dx)。此方法比较曲折。
我们把这个人从平地上放到了一个斜坡上, 只要他往下坡的方向走一点点, 由于向下的惯性, 他不自觉地就一直往下走, 走的弯路也变少了。这就是 Momentum 参数更新。
AdaGrad 优化学习率
AdaGrad 优化学习率,使得每一个参数更新都会有自己与众不同的学习率。与momentum类似,不过不是给喝醉酒的人安排另一个下坡, 而是给他一双不好走路的鞋子, 使得他一摇晃着走路就脚疼, 鞋子成为了走弯路的阻力, 逼着他往前直着走。
RMSProp
RMSProp 有了 momentum 的惯性原则 , 加上 adagrad 的对错误方向的阻力, 我们就能合并成这样。让 RMSProp同时具备他们两种方法的优势。不过细心的同学们肯定看出来了, 似乎在 RMSProp 中少了些什么。原来是我们还没把 Momentum合并完全, RMSProp 还缺少了 momentum 中的 这一部分。所以, 我们在 Adam 方法中补上了这种想法。
Adam
Adam 计算m 时有 momentum 下坡的属性, 计算 v 时有 adagrad 阻力的属性, 然后再更新参数时 把 m 和 V 都考虑进去。 实验证明, 大多数时候, 使用 adam 都能又快又好的达到目标, 迅速收敛。所以说, 在加速神经网络训练的时候, 一个下坡, 一双破鞋子, 功不可没。
原文链接:https://blog.csdn.net/qq_34690929/article/details/79932416
用torch搭建鸢尾花神经网络
了解了上面的API和之前学习TensorFlow的基础,很容易我们就能写出一个用torch搭建的神经网络了。数据集依然使用入门的鸢尾花数据集。
# 导入相关依赖
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from sklearn import datasets
import numpy as np
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris["data"].astype(np.float32) # X为(150,4)的array数组
y = iris["target"].astype(np.int64) # y为标签0,1,2
# 将数据分为训练集和测试集
# 将150个样本分成:训练:120;测试:30
train_ratio = 0.8
index = np.random.permutation(X.shape[0])
train_index = index[:int(X.shape[0] * train_ratio)]
test_index = index[int(X.shape[0] * train_ratio):]
X_train, y_train = X[train_index], y[train_index]
X_test, y_test = X[test_index], y[test_index]
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
torch.manual_seed(2)
self.fc1 = nn.Linear(4, 32)
self.fc2 = nn.Linear(32, 32)
self.fc3 = nn.Linear(32, 3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型、损失函数和优化器
model = Net()
# 选择交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 选择SGD随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 把数组转换成张量
inputs = torch.from_numpy(X_train)
labels = torch.from_numpy(y_train)
# 梯度清零
optimizer.zero_grad()
outputs = model(inputs)
# 计算loss
loss = criterion(outputs, labels)
# 计算梯度
loss.backward()
# 实现参数更新
optimizer.step()
# 每10轮记录一次loss
if epoch % 10 == 0:
print("Epoch: %d, Loss: %.4f" % (epoch, loss.item()))
# 评估模型
with torch.no_grad():
inputs = torch.from_numpy(X_test)
labels = torch.from_numpy(y_test)
outputs = model(inputs)
_, predictions = torch.max(outputs, 1) # 获得outputs每行最大值的索引
accuracy = (predictions == labels).float().mean() # (predictions == labels):输出值为bool的Tensor
print("Accuracy: %.2f %%" % (accuracy.item() * 100))训练效果如下图:
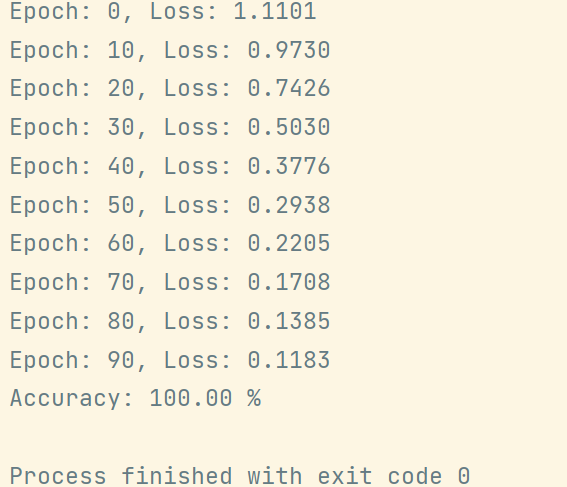
可以发现loss随着训练轮数增加逐渐下降,accuracy最后可以达到100%。其实对于鸢尾花识别数据集准确率是很容易到100%的。你也可以在继续深入学习Pytorch语法后去训练曾经在Tensorflow中训练过的MNIST数据集、FASHION数据集,还可以将loss曲线和accuracy曲线可视化表示。
至此,机器学习入门专题完结撒花,总共15篇文章分享,从基础的Numpy,Pandas工具介绍,到Tensorflow的介绍和使用,再到CNN,RNN的介绍,最后是Pytorch的简单使用。
前川已渡,后山可攀。共勉!
Comments NOTHING