
本文基于北京大学软件与微电子学院曹健老师的Tensorflow笔记整理 ——b站视频教程
数据增强,增大数据量
image_gen_train=tf.keras.preprocessing.image.ImageDataGenerator( 增强方法) image_gen_train.fit(x_train)
常用增强方法:
缩放系数:rescale=所有数据将乘以提供的值
随机旋转:rotation_range=随机旋转角度数范围
宽度偏移:width_shift_range=随机宽度偏移量
高度偏移:height_shift_range=随机高度偏移量
水平翻转:horizontal_flip=是否水平随机翻转
随机缩放:zoom_range=随机缩放的范围 [1-n,1+n]
例:image_gen_train = ImageDataGenerator(
rescale=1./255, #原像素值 0~255 归至 0~1
rotation_range=45, #随机 45 度旋转
width_shift_range=.15, #随机宽度偏移 [-0.15,0.15)
height_shift_range=.15, #随机高度偏移 [-0.15,0.15)
horizontal_flip=True, #随机水平翻转
zoom_range=0.5 #随机缩放到 [1-50%,1+50%]
断点续训,存取模型
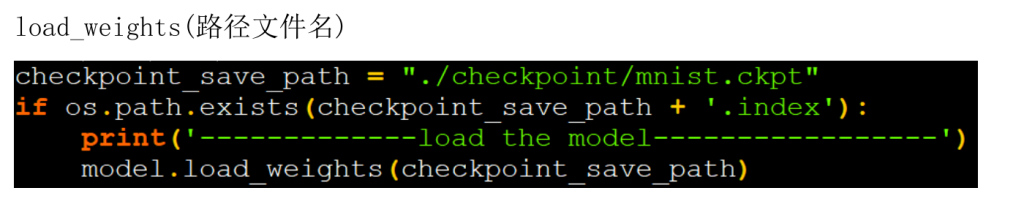
读取模型
保存模型

import tensorflow as tf
import os
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()参数提取,写至文本
提取可训练参数 model.trainable_variables 模型中可训练的参数
设置 print 输出格式
np.set_printoptions(precision=小数点后按四舍五入保留几位,threshold=数组元素数量少于或等于门槛值,打印全部元素;否则打印门槛值+1 个元素,中间用省略号补充)
np.set_printoptions(precision=5)
print(np.array([1.123456789]))
[1.12346]
np.set_printoptions(threshold=5)
print(np.arange(10))
[0 1 2 … , 7 8 9]
注:precision=np.inf 打印完整小数位;threshold=np.nan 打印全部数组元素。
np.set_printoptions(threshold=np.inf) # 打印参数设置无限大
print(model.trainable_variables) # 打印
file = open('./weights.txt', 'w') # 写至文本
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()acc/loss 可视化,查看效果
history=model.fit(训练集数据, 训练集标签, batch_size=, epochs=,
validation_split=用作测试数据的比例, validation_data=测试集,
validation_freq=测试频率)
history:
loss:训练集 loss
val_loss:测试集 loss
sparse_categorical_accuracy:训练集准确率
val_sparse_categorical_accuracy:测试集准确率

from matplotlib import pyplot as plt
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()功能扩展后的MNIST完整代码(☆)
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
np.set_printoptions(threshold=np.inf) # 打印参数设置无限大
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 导入数据集
x_train, x_test = x_train / 255.0, x_test / 255.0 # 数据归一化
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 断点续训
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# 参数打印 写入文件
print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()MNIST手写数字识别应用
from PIL import Image
import numpy as np
import tensorflow as tf
# 训练好的模型路径
model_save_path = './checkpoint/mnist.ckpt'
# 搭建前向传播
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')])
# 载入模型
model.load_weights(model_save_path)
preNum = int(input("input the number of test pictures:"))
for i in range(preNum):
image_path = input("the path of test picture:")
img = Image.open(image_path)
# 图片转成28*28像素的标准尺寸
img = img.resize((28, 28), Image.ANTIALIAS)
# 转换为灰度图
img_arr = np.array(img.convert('L'))
# 二值化 变为只有黑色和白色的高对比度图片,过滤去了背景噪声
for i in range(28):
for j in range(28):
if img_arr[i][j] < 200:
img_arr[i][j] = 255
else:
img_arr[i][j] = 0
# 归一化
img_arr = img_arr / 255.0
# 由于是batch形式送入,需要添加一个维度 变为(1,28,28)的三维数据
x_predict = img_arr[tf.newaxis, ...]
# 送入predict函数
result = model.predict(x_predict)
# 返回最大值的预测结果
pred = tf.argmax(result, axis=1)
print('\n')
tf.print(pred)
Comments NOTHING